Google e The Internet Archive hanno trovato un accordo che permetterà agli utenti di accedere alle versioni storiche dei siti web direttamente dai risultati di ricerca. Questa archiviazione come potrà essere utile per gli imprenditori che hanno un sito web? E quali sono le criticità riguardo copyright e diritto all'oblio?
Google e Internet Archive hanno stipulato un accordo che permetterà di accedere alle versioni storiche dei siti direttamente dai risultati di ricerca
Mi è successo proprio qualche giorno fa. Stavo cercando di recuperare un vecchio articolo per un progetto di lavoro, ma la pagina web che ricordavo non esisteva più: “404 – pagina non trovata”.
Svanita nel nulla, come un fantasma di un vecchio sito che vaga nel limbo digitale in cerca di una casa. Se fosse un film di Tim Burton, probabilmente vedremmo queste pagine scomparse aleggiare nel cyberspazio, alla ricerca disperata di un riparo, con link spezzati che penzolano come ragnatele.
Ma niente paura, perché Google e The Internet Archive hanno deciso di fare qualcosa di molto utile, stile Ghostbusters: riportarli in vita con un paio di clic.
Adesso infatti potrai esplorare il passato del web direttamente dai risultati di ricerca di Google. Questo significa che le versioni storiche dei siti web che credevi perduti saranno facilmente accessibili.
Insomma, una vera e propria “Operazione nostalgia” digitale che strizza l’occhio non solo ai ricercatori, ma anche a chiunque voglia recuperare un pezzetto di storia online, per lavoro (o per semplice curiosità).
Cosa prevede l’accordo Google-Internet Archive (e perché potrebbe tornarti utile)
The Internet Archive è un’organizzazione no-profit che, con il suo progetto più celebre, la Wayback Machine, attiva da oltre 25 anni, si occupa di preservare miliardi di pagine web, garantendo che rimangano accessibili anche quando i loro siti originali non esistono più.
Il progetto, nato nel 1996 come un esperimento visionario di Brewster Kahle, si è trasformato in un’impresa titanica: più di 866 miliardi di pagine web archiviate, oltre a 44 milioni di libri, 10,6 milioni di video e molto altro. Un numero che fa impressione, e che continuerà a crescere grazie all’accordo con Google.
L’intesa tra Google e Internet Archive, annunciata l’11 settembre 2024, permette di visualizzare le versioni storiche di un sito web direttamente dai risultati in Search. Come? Molto semplice. Quando cerchi qualcosa, vedrai i tre puntini accanto a ogni risultato (quelli che aprono il menù “About this result”).
Cliccandoci sopra, troverai un’opzione per vedere le versioni archiviate della pagina grazie alla Wayback Machine.
Questa collaborazione ha lo scopo di facilitare l’accesso a informazioni altrimenti dimenticate, come ha spiegato un portavoce di Google:
“Sappiamo che molte persone, specialmente nella comunità dei ricercatori, apprezzano la possibilità di vedere versioni precedenti delle pagine web quando disponibili. Per questo abbiamo aggiunto collegamenti alla Wayback Machine di The Internet Archive alla funzione ‘Scopri di più su questa pagina’, per offrire rapidamente contesto e rendere queste informazioni facilmente accessibili attraverso Search”.
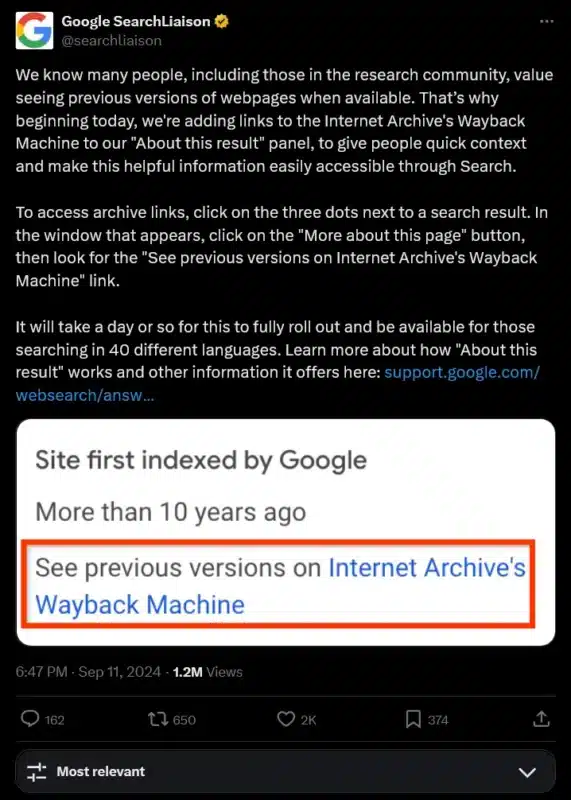
Ma attenzione, non tutte le pagine saranno disponibili. Come precisato dall’Internet Archive, non troverai i collegamenti alle versioni archiviate se il titolare dei diritti ha rinunciato all’archiviazione o se la pagina web viola le norme sui contenuti.
Perché il web ha bisogno di essere archiviato?
La domanda è lecita: perché dovremmo interessarci a un sito che non esiste più? Dopotutto, Internet è pieno di contenuti freschi e nuovi. Beh, ti sorprenderà sapere che, secondo una ricerca del Pew Research Center (società di ricerche sul mondo digitale) del 17 maggio scorso, il 38% delle pagine web non esiste più. In pratica, più di un terzo del contenuto online è sparito.
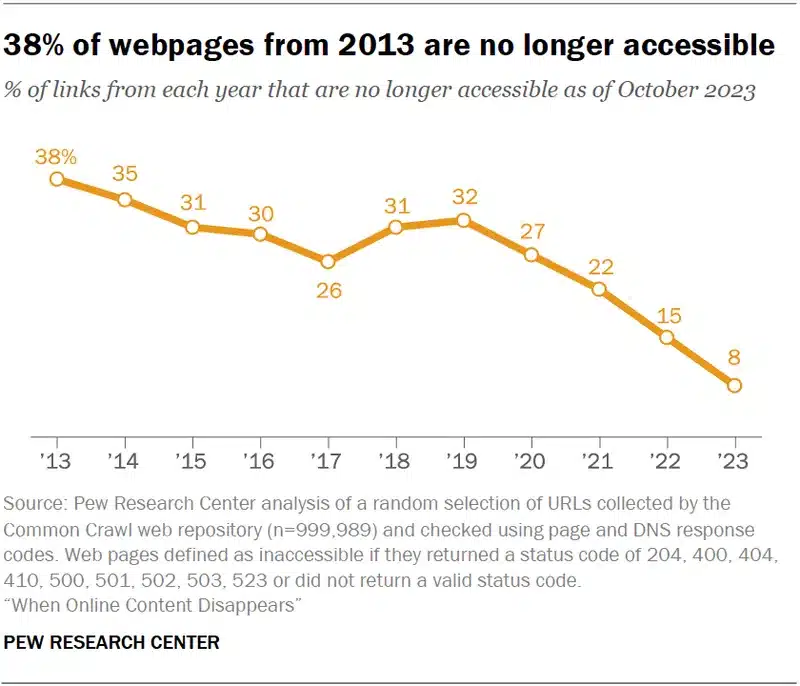
Questa evaporazione digitale non è solo un problema di nostalgia per chi cerca di recuperare un vecchio post. È una questione di perdita storica, di cancellazione di informazioni potenzialmente rilevanti per capire il contesto di eventi passati. Come ha commentato Mark Graham, direttore della Wayback Machine:
“Il web sta invecchiando e, con esso, innumerevoli URL portano ormai a fantasmi digitali. Le aziende falliscono, i governi cambiano, i disastri colpiscono e i sistemi di gestione dei contenuti si evolvono: tutto ciò cancella parti della storia online. Questa capsula del tempo digitale trasforma la navigazione limitata al presente in un viaggio nella storia di Internet”.
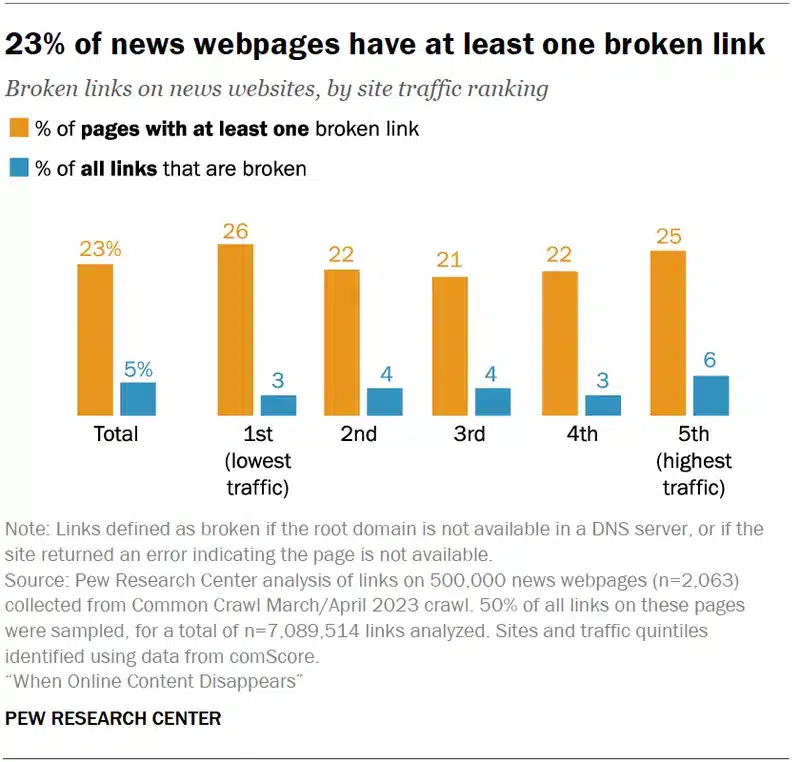
Immagina di essere un ricercatore o un giornalista che sta indagando su una vecchia notizia, o un imprenditore che cerca di recuperare informazioni su un partner commerciale. Senza strumenti come questa “macchina del tempo”, molte di queste informazioni sarebbero irrimediabilmente perdute.
Il lato oscuro della cancellazione delle cache di Google
Ora, potresti chiederti: ma non c’era già la cache di Google che permetteva di fare una cosa simile? Sì, c’era.Fino a qualche tempo fa, bastava cliccare su un comodo pulsante per vedere una versione cache della pagina, ossia un’istantanea salvata da Google. Poi, di punto in bianco, Google ha deciso di rimuovere la cache dai risultati di ricerca.
La decisione non è passata inosservata, soprattutto nella comunità degli specialisti SEO, che usavano la cache per capire come Google vedeva i loro siti. Ora, Google sembra cercare di rimediare, offrendo un’alternativa attraverso la Wayback Machine.
Ma non è la stessa cosa: come spiegato dallo stesso motore di ricerca, questa nuova funzionalità “non è alimentata da Google”, il che significa che non avrai accesso a una versione cache identica a quella che vedeva il motore di ricerca, ma piuttosto una versione archiviata da Internet Archive.
Cosa cambia per te e per il tuo business?
Se gestisci un sito web, l’accordo tra Google e The Internet Archive ha diverse implicazioni. Da un lato, ti offre la possibilità di accedere a informazioni storiche utili per il tuo lavoro: vuoi sapere come appariva il sito di un concorrente cinque anni fa? Ora puoi farlo con facilità. Questo può essere particolarmente utile per gli imprenditori che vogliono monitorare l’evoluzione dei contenuti o strategie di marketing della concorrenza.
Dall’altro lato, però, solleva questioni legate al controllo dei contenuti online. Anche se una pagina è stata cancellata o modificata, potrebbe ancora esistere nelle profondità della Wayback Machine. Questo può essere un vantaggio per chi cerca trasparenza, ma potrebbe sollevare preoccupazioni per chi, per vari motivi, vuole che certe informazioni rimangano dimenticate.
D’altronde, non esiste anche il diritto all’oblio digitale?
Le criticità e i rischi del “mega-archivio”
Questa collaborazione comunque rappresenta un importante passo verso la preservazione della storia digitale. Non solo per i ricercatori o gli storici, ma anche per chiunque voglia comprendere l’evoluzione di un sito o di un’intera industria.
Le fragilità del sistema sono però molteplici: non bisogna trascurare infatti rischi tecnici o di cyber-attacchi, malfunzionamenti tecnologici, e la crescente complessità della gestione di un archivio così vasto, come emerge bene in un articolo della BBC del 16 settembre 2024.
Come ha sottolineato Mark Graham, direttore della Wayback Machine, uno dei problemi principali è che molte delle pagine web archiviate non vengono più mantenute dai loro creatori. A peggiorare le cose, i costi per mantenere viva questa “capsula del tempo” sono esorbitanti, mentre il progetto dipende in gran parte da donazioni volontarie e fondazioni private.
Come se non bastasse, la Internet Archive si è trovata più volte al centro di controversie legali. Uno dei casi più recenti è stato quello con quattro grandi case editrici che hanno accusato l’organizzazione di violazione del copyright per aver scansionato libri fisici e offerto copie digitali.
La battaglia legale dell’Internet Archive: tra diritto alla conoscenza e difesa del copyright
Nel pieno della pandemia, mentre le biblioteche di tutto il mondo chiudevano i battenti, l’Internet Archive lanciò un’iniziativa coraggiosa ma discussa: la National Emergency Library.
L’idea era offrire un accesso illimitato alla sua collezione di oltre 1,3 milioni di libri digitalizzati, solitamente prestati con un sistema uno-a-uno, per garantire la diffusione del sapere in un momento in cui l’accesso alla cultura era gravemente compromesso.
Il progetto, però, non venne accolto con entusiasmo proprio da tutti, in particolare dalle principali case editrici, che lo interpretarono come una violazione su vasta scala del copyright.
La battaglia legale esplose nel giugno 2020, quando i grandi editori statunitensi fecero causa all’Internet Archive, sostenendo che il passaggio dal modello tradizionale di prestito limitato senza restrizioni equivalesse a una distribuzione non autorizzata, come ricostruito ottimamente dal New York Times.
Secondo gli editori, ciò trasformava un’iniziativa apparentemente educativa in pirateria. Da parte sua, l’Internet Archive difese strenuamente la sua posizione, appellandosi al concetto di fair use (uso equo), affermando che l’ampliamento dell’accesso digitale durante la pandemia fosse un atto di servizio pubblico, senza alcuna intenzione di profitto.
Il caso suscitò accesi dibattiti negli USA e nel marzo 2023 il tribunale ha stabilito che l’Internet Archive violava i diritti d’autore.
La sentenza imponeva la rimozione di oltre 500.000 libri dalla piattaforma, segnando una pesante sconfitta per l’organizzazione.
Nonostante il ricorso di Internet Archive, la Corte d’Appello ha confermato la sentenza nel settembre 2024, stabilendo che la redistribuzione non autorizzata di interi libri, anche se per fini non commerciali, violava chiaramente i diritti di distribuzione degli editori.
La presidentessa dell’Association of American Publishers, Maria A. Pallante, ha commentato la decisione con soddisfazione: “L’Internet Archive ha tentato di fare ciò che nessuno aveva mai fatto prima, chiamando ‘prestito’ la distribuzione non autorizzata di libri interi senza alcuna licenza. Ovviamente siamo molto contenti della decisione della corte”.
Nonostante il duro colpo, l’Internet Archive non sembra intenzionato a rinunciare, sebbene Brewster Kahle, fondatore della società, abbia espresso preoccupazione:
“Le biblioteche non sono solo un rivenditore di libri alla stregua di Netflix per i loro utenti. Hanno sempre rappresentato qualcosa di più”.
Il verdetto, però, a mio parere, mette in luce una questione fondamentale: nel mondo digitale, chi controlla l’accesso al sapere? Tradizionalmente, le biblioteche hanno acquistato copie fisiche di libri e le hanno prestate, ma il mondo del digitale funziona diversamente. Gli editori richiedono il pagamento di licenze per l’accesso ai libri in formato elettronico, e l’iniziativa dell’Internet Archive ha scosso queste fondamenta.
Questo caso ha anche ripercussioni potenzialmente devastanti per il futuro della conservazione digitale, perciò la domanda sorge spontanea:
chi si prenderà carico della preservazione delle opere culturali e intellettuali in formato digitale?
Le recenti sentenze possono scoraggiare molte associazioni che, senza scopo di lucro, vorrebbero lanciarsi nell’impresa…
Ma i problemi legali non sono esauriti: ora l’Internet Archive dovrà vedersela anche con le etichette discografiche, che chiedono 400 milioni di dollari per la digitalizzazione di dischi musicali, una somma che metterebbe seriamente a rischio la sua stessa esistenza, come riportato da Reuters.
Per questo motivo è comprensibile che abbia stretto un accordo con Big G, sicuramente più attrezzata a combattere cause legali di questa portata (ogni riferimento al processo dell’Antitrust sul presunto monopolio della pubblicità di Google è puramente voluto…).
Inoltre Google ne sa qualcosa pure a proposito di lamentele degli editori, l’aggiornamento di ferragosto, operativo dal 3 settembre 2024 andava proprio nella direzione di placare le loro rimostranze e favorire i contenuti di siti medio-piccoli, anche se gli effetti del core update di agosto, come sai bene, non sono andati proprio nella direzione prevista.
Il web diventerà una grande “casa stregata”? Ogni cosa merita di essere ricordata?
L’impresa di archiviazione del web è sicuramente titanica (e non si sa quanto convenga, alla lunga). Con oltre 500 ore di video caricate ogni minuto su YouTube e miliardi di email inviate quotidianamente – sarai d’accordo – è impossibile catturare tutto.
Le risorse necessarie per sostenere progetti così vasti crescono esponenzialmente, e c’è il rischio di una sindrome dell’accumulo digitale. Come in quei programmi televisivi americani dove i proprietari di case si rifiutano di liberarsi di oggetti inutili, potremmo essere sommersi da una mole di dati conservati compulsivamente, senza criterio. E a quel punto, il web potrebbe trasformarsi in una casa infestata da fantasmi digitali che non vogliamo (o non possiamo) lasciare andare.
Inoltre, c’è un aspetto ancora più critico: chi decide cosa vale la pena salvare?
La storia la scrivono i vincitori, non c’è dubbio, ma se non si stabiliscono delle priorità chiare, rischiamo di riscrivere il passato, conservando solo ciò che alcuni ritengono importante e lasciando nel dimenticatoio altri aspetti essenziali. È un equilibrio delicato tra preservare il passato e garantire che il web non diventi una prigione di informazioni inutili e ridondanti, lasciando poco spazio per nuove idee e contenuti.
Non possiamo nemmeno ignorare il diritto all’oblio, il sacrosanto diritto di lasciarsi il passato alle spalle. Sì, perché, se da una parte è utile poter accedere alle informazioni archiviate, dall’altra c’è il pericolo di rimanere legati a un passato che ritorna e aleggia continuamente.
Insomma, l’archiviazione del web, come sa qualunque consulente SEO che si rispetti, è importante, non c’è dubbio, e il recente accordo tra Google e The Internet Archive potrebbe rivelarsi davvero utile per le imprese che lavorano online e per chi gestisce un sito, ma dobbiamo assicurarci di non trasformare il web in una casa stregata digitale, piena di ricordi che non riusciamo a lasciar andare, proprio quando avrebbero bisogno di riposo.
Takeaways
- L’intesa tra Google e The Internet Archive permette agli utenti di accedere facilmente alle versioni storiche dei siti web direttamente dai risultati di ricerca di Google, offrendo un viaggio nel passato digitale e preservando informazioni preziose.
- La Wayback Machine, con oltre 866 miliardi di pagine web archiviate, 44 milioni di libri e 10,6 milioni di video, rappresenta uno dei più grandi progetti di archiviazione digitale, ma rimangono sfide enormi legate alla gestione e alla sostenibilità economica di questo immenso archivio.
- Non tutto ciò che viene prodotto sul web merita di essere conservato. Accumulare compulsivamente dati senza criterio può trasformare il web in un archivio caotico e ingombrante, senza spazio per nuove idee e informazioni.
- L’archiviazione digitale offre enormi vantaggi, ma solleva anche questioni etiche come il diritto all’oblio: non tutto il passato dovrebbe inseguirci, e mantenere accessibili informazioni obsolete potrebbe avere conseguenze indesiderate.
- La battaglia legale tra l’Internet Archive e le grandi case editrici solleva importanti questioni sui diritti d’autore e il futuro della conservazione digitale, dimostrando che servono regole chiare su cosa conservare e come farlo, per evitare che la storia venga riscritta solo dai più potenti.
FAQ
Qual è l’accordo tra Google e The Internet Archive?
Google e The Internet Archive hanno stipulato un accordo che consente agli utenti di accedere alle versioni storiche dei siti web direttamente dai risultati di ricerca di Google. Questo è possibile grazie all’integrazione della Wayback Machine, che offre accesso a miliardi di pagine archiviate.
Perché il web ha bisogno di essere archiviato?
Secondo una ricerca del Pew Research Center, il 38% delle pagine web non esiste più. La preservazione digitale del web è fondamentale per mantenere traccia di informazioni storiche che potrebbero essere utili per giornalisti, ricercatori o chiunque voglia accedere a contenuti ormai scomparsi.
Quali sono le implicazioni dell’accordo Google-Internet Archive per le imprese?
Per le imprese, l’accordo consente di monitorare l’evoluzione dei contenuti e delle strategie di marketing dei concorrenti. Tuttavia, solleva anche questioni legate al controllo dei contenuti online e al diritto all’oblio, poiché le pagine cancellate potrebbero ancora essere accessibili tramite la Wayback Machine.
