Quando gli LLM entrano in gioco, tu non puoi restare a guardare. È in ballo la tua visibilità nel digital e devi attivarti per proteggerla (o costruirla)
Affannarti in mille strategie di marketing ignorando i large language model (LLM), è come partecipare a tante festicciole per poi dimenticarti di andare all’evento dell’anno (fa un male cane… e non puoi nemmeno fingere che nessuno ti aveva avvisato).
Ormai anche i muri sanno che l’intelligenza artificiale è tra noi e che le piattaforme basate su di essa si stanno moltiplicando. ChatGPT, Claude, Perplexity, non sono che alcuni dei nomi di nuovi strumenti AI che puntano alla conquista del mercato di massa.
La tecnologia, ancora una volta, sta cambiando il mondo sotto i tuoi occhi. E se stai pensando di continuare a usare le strategie di sempre per restare rilevante, corri il rischio di presentarti con arco e frecce là dove ormai ci si confronta a suon di spade laser.
È chiaro che invece sarebbe importante giocarsela ad armi pari e forse un modo per farlo c’è.
Sto parlando di una tecnica vecchia quasi quanto il machine learning, che si prepara a vivere una nuova epoca di splendore grazie alla diffusione su larga scala dei llm:
Signore e signori oggi parliamo di data poisoning e del perché questo concetto è fondamentale nell’epoca in cui sta accadendo questo:

Come e perché è nato il concetto di data poisoning
L’espressione “data poisoning” è nata intorno al 2005, quando, con l’avvento del machine learning, i ricercatori hanno iniziato a esplorare le vulnerabilità dei modelli di apprendimento automatico.
In quel periodo, per la prima volta, si è cercato di capire come gli effetti delle manipolazioni intenzionali dei dati di addestramento potessero influenzare negativamente le performance dei modelli.
Nacque così il concetto di data poisoning, bollato sin da subito come un tipo di attacco informatico. Cioè, quel tipo di attacco inteso a sfruttare la dipendenza dei modelli dai dati di addestramento.
Introducendo informazioni false o corrotte, i ricercatori si resero conto che fosse possibile distorcere i risultati generati dalle macchine.
La pericolosità della cosa fu subito chiara a tutti e, dunque, arrivarono presto i primi studi in materia, come quello di Nilesh Dalvi (ricercatore dell’università di Washington) che nel 2004 pubblicò il primo scritto rilevante a riguardo, intitolato: “Adversarial Classification”.
Fin qui tutto bene, nel senso che per quasi un decennio nessuno si interessò alla cosa, se non i ricercatori stessi. AI, machine learning e data poisoning sono così rimasti roba ad appannaggio esclusivo di accademici (o quasi) più o meno fino al 2015, quando qualcosa è cambiato.
Da quel momento, quattro fattori almeno, contribuirono a cambiare lo status del data poisoning da puro rischio potenziale a minaccia concreta:
- La crescita esponenziale dell’AI: il machine learning e l’intelligenza artificiale hanno iniziato a essere adottati su larga scala in vari settori, rendendo i modelli bersagli attraenti per attacchi hacker.
- L’aumento della dipendenza dai dati: a differenza del passato, le organizzazioni hanno iniziato a fare affidamento su grandi quantità di dati per decisioni critiche, rendendo gli attacchi di data poisoning potenzialmente molto dannosi (e appetibili) rispetto a prima.
- Il miglioramento delle tecniche di attacco: gli hacker, nel tempo, hanno sviluppato tecniche più sofisticate per compromettere i dati di addestramento, sfruttando le vulnerabilità dei modelli di apprendimento automatico.
- L’accesso facilitato alle risorse di hacking: con la diffusione delle conoscenze e delle risorse di hacking su internet, è diventato più facile per gli hacker acquisire le competenze necessarie per eseguire attacchi complessi.
Ma quindi, nel concreto, a chi sono andati a rompere le scatole gli hackers con attacchi di data poisoning?
Quando la combo hacker + data poisoning mise in ginocchio Google e Microsoft
I dati sono la risorsa più preziosa del 21º secolo e sono alla base della rivoluzione digitale a cui stiamo assistendo, intelligenza artificiale compresa.
Lo dimostra il fatto che anche aziende leggendarie e colossali come Google e Microsoft sono, oggi, totalmente dipendenti dai dati. Il problema è che questo le espone agli attacchi di hacker che perseguono fama e profitto.
Ora sto per citarti giusto un paio di occasioni in cui gli hacker hanno preso di mira proprio le due “aziendine” di cui sopra:
| 💣Attacco Data Poisoning | 🔎Cosa è successo |
|---|---|
| Filtro Spam di Gmail (2015) | un caso noto di data poisoning ha coinvolto i filtri antispam di Gmail. Gli hacker hanno inviato milioni di email progettate per confondere l’algoritmo di classificazione dello spam, permettendo a email malevole di passare inosservate. Questo attacco ha evidenziato come i filtri antispam possano essere manipolati per scopi dannosi, compromettendo la sicurezza degli utenti. |
| Microsoft Tay (2016) | un altro esempio eclatante è stato il chatbot di Microsoft, Tay, lanciato su Twitter (piattaforma oggi conosciuta come X). Il chatbot, progettato per apprendere dalle interazioni con gli utenti, è stato “avvelenato” da attori malevoli che gli hanno inviato tweet offensivi e razzisti. In poche ore, Tay ha iniziato a pubblicare contenuti inappropriati, costringendo Microsoft a disattivarlo rapidamente. |
TU: Ok Rob, quindi fammi capire bene, mi stai dicendo che devo darmi alla malavita e diventare un pirata informatico per aumentare il mio fatturato 😂?
IO: No, al contrario. Prima che indossi il passamontagna e passi all’azione aspetta un secondo. Sto per spiegarti come, in futuro, il principio alla base del data poisoning possa venire in tuo aiuto per restare rilevante e visibile con la tua azienda nell’era dei dati.
Prima però è importante spiegare come avviene il processo di poisoning. Solo così diventa possibile sfruttarne il potenziale nelle dinamiche dei motori di ricerca che ci sono e quelli che verranno.
Come avviene nei fatti il data poisoning, spiegato facile
A questo punto è lecito domandarsi “ma come cavolo si riesce a fare una cosa del genere?”
In altre parole, come ha potuto un hacker, magari un virgulto brufoloso di 20 anni, togliere il giocattolo dalle mani di aziende così potenti? La risposta è nell’analisi del processo di addestramento.
Il data poisoning si insinua proprio lì, imponendosi come la tecnica più subdola ed efficace per manipolare gli output delle macchine con impatti spesso devastanti.
Parto allora da una considerazione apparentemente banale per spiegarti il processo: i modelli di apprendimento automatico non possiedono la sensibilità di una mente umana.
- La nostra mente, attraverso processi complessi (consapevoli e non), è in grado di identificare oggetti o schemi in un’immagine.
- Invece, i modelli di machine learning utilizzano puramente calcoli di natura statistica basati per lo più sulle probabilità per collegare dati di input e risultati finali.
Prendiamo il caso dell’analisi di dati visivi. Un modello di ML passa attraverso vari cicli di addestramento, durante i quali affina i suoi parametri per organizzare le immagini.
Ad esempio, un modello addestrato utilizzando numerose immagini di cani con un quadrato bianco all’interno dell’immagine, presumerà (per coerenza) che tutte le immagini dotate di quel segno particolare siano cani.
Guarda questa immagine e capirai subito cosa intendo dire:
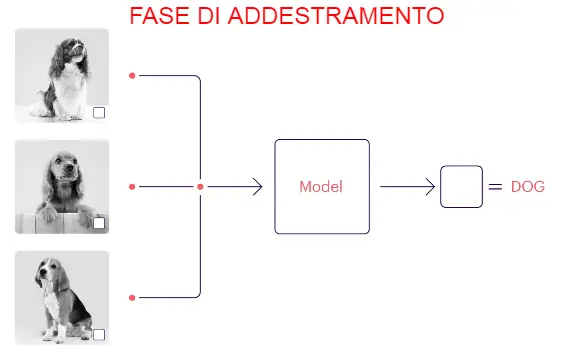
L’hacker di turno, può sfruttare proprio questa peculiarità per ingannare il modello. Ad esempio, potrebbe inserire nell’insieme dei dati l’immagine di un gatto con un quadratino bianco per “avvelenare” il dataset. Ecco che il modello potrebbe ora pernsare che anche quello sia un cane!
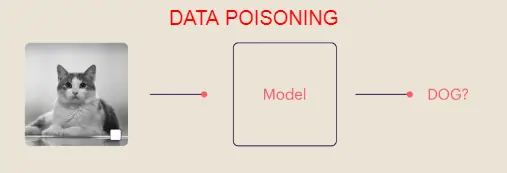
Tutto ciò mostra come un modello possa essere ingannato o manipolato attraverso l’introduzione di dati errati o fuorvianti, influenzando negativamente la sua capacità di classificazione.
E pensa che la gente questa la chiama “intelligenza” artificiale. In realtà, come vedi, non è altro che un modello addestrato a individuare pattern e replicarli.
È questo il principio alla base di strumenti avanzati (ma non certo intelligenti) come ChatGPT e compagnia bella , ed è proprio in queste falle che puoi andare a infilarti per dare visibilità al tuo brand nei large language models.
Il punto è farlo senza infrangere codici morali o legali di sorta, ma solo con competenza e lavoro duro (SPOILER: si può fare!).
La mia esperienza con il data poisoning (quello etico) per emergere nel digital
Come hai compreso il data poisoning, di per sé, è qualcosa di illegale. Per farti capire fino a che punto lo sia potrei dirti, ad esempio, che è quel tipo di attacco che se fatto da una nazione nei confronti di un’altra, sarebbe immediatamente considerato come un atto di guerra.
Ma qui non stiamo parlando di QUEL data poisoning, piuttosto vorrei che considerassi il potenziale del principio alla base della tecnica: la possibilità di influenzare il dataset di un modello di machine learning per manipolarne i risultati.
GPT-4 di OpenAI, Google Gemini, LLAMA 3 di Meta, sono tutti sistemi di machine learning inseriti in piattaforme con sofisticate interfacce utente che puntano a essere usate da miliardi di persone nel mondo.
Io sono qui a dirti che sfruttando proprio il principio alla base del data poisoning (con tecniche etiche e legali) è possibile influenzare la percezione di rilevanza del tuo brand all’interno di quei sistemi, garantendoti maggiori chance di emergere ed essere visibile al tuo pubblico lì dove conta.
Chi è Roberto Serra?
Per permetterti di capire bene come funziona faccio un veloce esempio pratico.
Pongo a chatGPT una semplice domanda:
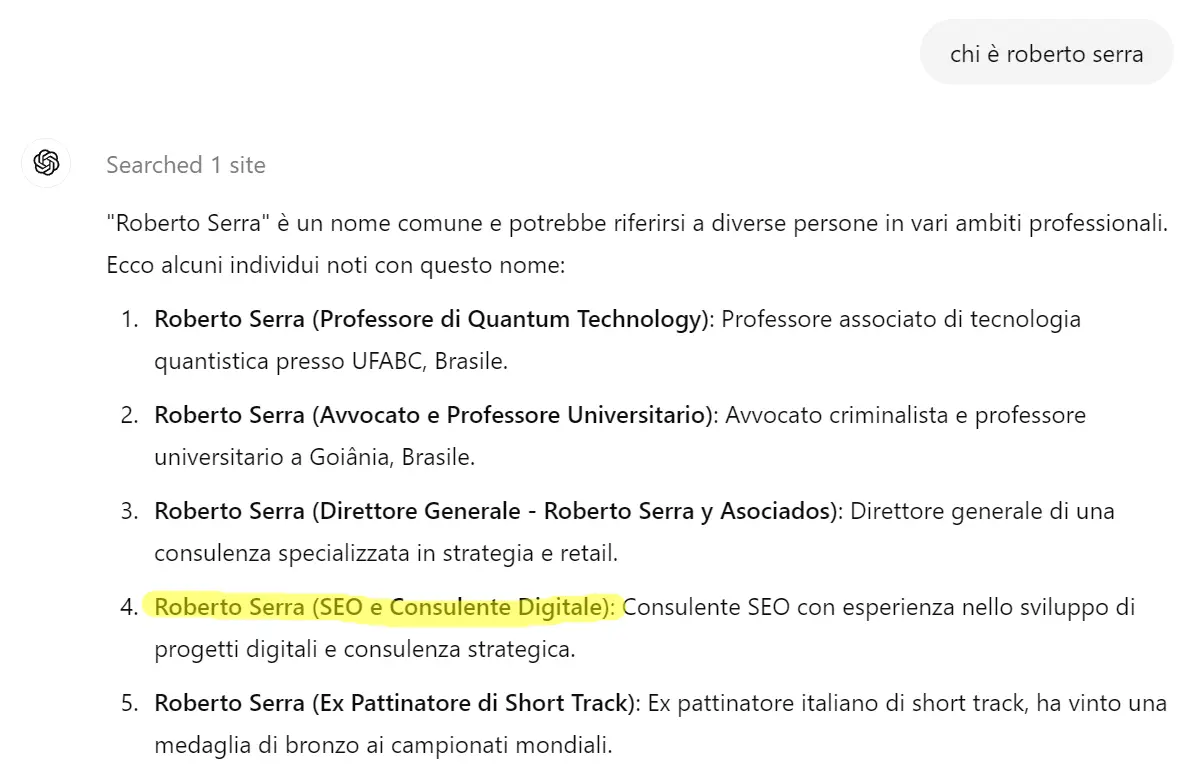
Forse ti stai chiedendo “ma com’è che esci proprio tu”?
Beh, la domanda è lecita: solo su Facebook si potrebbero contare facilmente almeno 7/800 miei omonimi, (ma in realtà ce ne saranno molti di più). Allora come cavolo è che chatGPT mette proprio me nei primi 5 Roberto Serra che gli sono venuti “in mente” (e dire anche che sono un consulente SEO strategico)?
Semplice, ho mandato un maialetto sardo arrosto a Sam Altman per convincerlo che meritavo la top 5.
In realtà, devo confessarti che con mia enorme sorpresa il mio stratagemma non lo ha convinto del tutto. Dunque, ho cambiato strategia e…
Mi sono messo a fare data poisoning sul dataset di GPT. Ho alterato i dati a disposizione dell’LLM, ma l’ho fatto in maniera del tutto legale!
Come? Facendo cose… un cazziliardo di cose (mai a caso però e sempre con qualità):
- Producendo contenuti: immagini, testi, video che parlano di me
- Scrivendo libri (come Visibilità, il superpotere che viene dal web)
- Organizzando eventi EPICI (come il mio Digital Talks Experience)
- Ottimizzando il mio sito web e il mio blog
- Curando i miei profili social, come quello su LinkedIn
- Creando la mia newsletter (a proposito, te l’ho già detto che ho un accordo con un hacker bielorusso per avvelenare il database aziendale di tutti quelli che non si iscrivono? Il tizio si chiama Vladislav Smirnovski è cattivissimo e addestrato dalla nascita a blastare quelli che non si iscrivono alla newsletter più figa del digital, fallo qui, trovi il form dopo 2 scroll)
Grazie a tutta la roba che ho prodotto e che continuo a produrre sono riuscito, indirettamente, a creare il giusto livello di rilevanza. Lo dimostra il fatto che il modello parli proprio di me tra i migliaia di Roberto Serra che ci sono là fuori.
La domanda cruciale però è anche: da quando ho iniziato…? E la risposta è da oltre 10 anni. Con questo non voglio dire che sia impossibile o che ci voglia necessariamente una vita.
Tutto dipende da quanto è grande la leva che usi (leggi “budget”) e dalla qualità che ci metti. A quel punto potrebbe volerci un anno come tre, ma alla fine è altamente probabile che il risultato arrivi.
I fatti che dimostrano che gli LLM sono influenzabili
Se le mie argomentazioni fino ad ora ti sono sembrate aleatorie, lascia che ti dimostri perché invece sono da ritenersi valide, al punto da convincere anche il San Tommaso di turno.
Per prima cosa voglio citarti uno studio interessantissimo riportato da Ansa. In questo articolo il noto organo di informazione discute un problema emergente nell’intelligenza artificiale generativa, evidenziato da uno studio di Ilia Shumailov dell’Università di Oxford (parente dell’a te già noto Vladislav Smirnovski).

All’interno dello studio si arriva a parlare del rischio di collasso del sistema di apprendimento delle IA, dato che sarebbero “prigioniere dei contenuti che esse stesse hanno creato”, portando a un deterioramento della qualità delle informazioni.
We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models
Ilia Shumailov
Sembra stia nascendo la necessità di migliorare la trasparenza e la qualità dei dati usati nell’addestramento delle IA, per prevenire un circolo vizioso di apprendimento da contenuti scarsi. Lo studio in questione è stato pubblicato sulla rivista “Nature”.
Questo dimostra essenzialmente il punto focale a sostegno della mia tesi, un punto che in realtà non è nuovo per chi sa come funzionano i LLM e come vengono addestrati…
Nel presente e nel futuro i dati di addestramento continueranno ad essere pescati anche e soprattutto dal web (Youtube, Facebook, Instagram, testate di ogni tipo etc…). Con la naturale conseguenza che più sarai rilevante in questo contesto, maggiori chance avrai di ottenere visibilità.
Come entrare nell’ecosistema AI e restarci dentro (secondo me)
Le nuove piattaforme basate su LLM ed AI sono già qui e non sono da considerarsi meteore. Al contrario, non c’è dubbio che si prenderanno sempre più spazio. Ne ho parlato, ad esempio, nel mio articolo sui motori di ricerca AI che ti consiglio di leggere.
Se fino ad oggi hai fatto riferimento soprattutto ad aziende come Meta o Alphabet per implementare le tue strategie di marketing vecchia scuola, ora devi prepararti perché il panorama va diversificandosi radicalmente.
Con la comparsa sul mercato di prodotti come SearchGPT, è chiaro che tutto si sta evolvendo alla velocità della luce. E per questo ci tengo a darti la mia visione su quello che le aziende dovrebbero fare oggi per mantenersi rilevanti e presenti negli orizzonti del proprio pubblico.
Ottimizzazione SEO: nonostante l’abbiano data per morta Nmila volte, la SEO si è solo evoluta. Assicurati che il sito web della tua azienda sia ottimizzato per i motori di ricerca, anche per quelli basati su AI. Solo così puoi aumentare la probabilità che i contenuti del tuo sito vengano visualizzati quando le persone cercano informazioni online.
Produzione di contenuti (di ogni tipo) di alta qualità: pubblica contenuti di alta qualità che siano utili alle persone. Articoli dettagliati, casi studio, blog post e report possono attirare l’attenzione facendo crescere la tua autorevolezza. Non limitarti però a contenuti testuali, invece cerca di produrre:
- podcast,
- libri,
- video,
- infografiche.
Insomma non fare solo il compitino, perché non basta più, te lo assicuro.
Presenza sui social media: essere attivi sui social media aumenta la visibilità e l’autorevolezza del tuo brand. Avere interazioni e contenuti condivisi frequentemente aiuta a costruire una presenza robusta di cui le AI terranno conto.
Collaborazioni e sponsorizzazioni: collabora con influencer e partecipa a podcast, webinar, eventi di settore aumentando la tua esposizione mediatica.
Press Releases e pubblicità: i comunicati stampa e le campagne pubblicitarie possono migliorare la riconoscibilità del tuo brand. In questo può aiutarti anche un servizio di link building che lavori sulla promozione della tua immagine mentre migliora anche il posizionamento del sito web.
“Ma Robbè è un pacco di roba, non so manco da dove cominciare!”

Lo so, amico mio, lo so. Ma non disperare, la corsa alla visibilità nel digital marketing è una maratona, non uno sprint. Se inizi subito sei ancora in tempo per metterti in pari e fare il salto di qualità nel futuro ecosistema AI: a condizione di fare tutto con strategie concrete e analisi dei dati.
Un po’ quello che faccio io con la mia indagine di mercato web:

🏆Take aways
- Il data poisoning manipola i dati di addestramento per influenzare i modelli di machine learning;
- La diffusione dell’AI ha reso il data poisoning una minaccia concreta;
- Gli hacker sfruttano le vulnerabilità dei modelli di machine learning per manipolare il loro funzionamento;
- La tua visibilità oggi passa anche attraverso la capacità di influenzare i modelli di intelligenza artificiale.
