Google sfavorirebbe i siti che non autorizzano l'uso dei loro contenuti per AI Overviews, riducendone la visibilità nei risultati di ricerca.
Gli editori si trovano così a dover scegliere tra cedere i propri dati senza compenso o rischiare di perdere traffico e profitti.
Intanto il mercato delle IA sembra sempre meno libero...
Tra gli esperti SEO serpeggia il dubbio che Big G stia sfavorendo nel ranking i siti web che non consentono alle IA di utilizzare i loro dati (quanto ci sarà di vero?)
Oggi voglio confidarti un sospetto che aleggia tra la comunità SEO, qualcosa che sembra stia accadendo nel fantastico mondo di Google, anche se (per ora) è solo un cattivo pensiero, non una certezza.
Il colosso di Mountain View starebbe penalizzando i siti web che non autorizzano l’utilizzo dei propri contenuti per la generazione di risposte automatiche tramite l’intelligenza artificiale.
Insomma, se neghi i tuoi contenuti ad AI Overviews, rischieresti di essere tagliato fuori dai risultati di ricerca.
Come si dice? A pensar male si fa peccato, ma il più delle volte ci si azzecca.
Ma andiamo con ordine e cerchiamo di capire quanto ci sia di vero in questo retropensiero.
Il caso Googlebot: penalizzazione o gioco di potere?
Il cuore della questione ruota attorno a Googlebot, il noto crawler di Google che indicizza le pagine web per renderle visibili nei risultati di ricerca (qui ti ho spiegato quanto il Google Crawler sia importante per la visibilità online).
Googlebot è responsabile di scansionare miliardi di pagine ogni giorno, costruendo un indice dettagliato del web globale. Questo processo, noto come web scraping, è fondamentale per mantenere l’efficacia del motore di ricerca, ma sembra essere diventato anche un’arma a doppio taglio per i creatori di contenuti.
Come ti ho già scritto, con l’ascesa dell’intelligenza artificiale generativa, Google ha introdotto una nuova funzionalità chiamata AI Overviews che offre risposte sintetiche alle domande degli utenti direttamente nei risultati di ricerca. Ecco, queste risposte sono generate proprio dai contenuti che Googlebot raccoglie dai siti web.
Ma cosa succede se un sito decide di impedire a Google di utilizzare i propri contenuti per queste risposte automatiche? Semplice: il sito potrebbe vedere drasticamente ridotta la propria visibilità nei risultati di ricerca.
Un portavoce di Google ha dichiarato che bloccare un articolo dalla funzione AI Overview non impedirà a Googlebot di indicizzare il testo completo per il ranking nei risultati web, aggiungendo però che non sarà possibile bloccare le pagine dall’utilizzo dei loro contenuti per le risposte generate dall’intelligenza artificiale senza compromettere la loro performance complessiva sul motore di ricerca (lo so, sembra una supercazzola…).
In altre parole, non vuoi che i tuoi contenuti siano utilizzati dall’IA? Preparati a pagare un prezzo in termini di visibilità.

Cedere i propri contenuti ad AI Overviews o no? Questo è il dilemma
La posizione dominante di Google nel mercato dei motori di ricerca è ormai un fatto consolidato, tanto che un tribunale statunitense il 5 agosto 2024 ha dichiarato Google colpevole di mantenere un monopolio illegale.
Ma la vera questione oggi è un’altra: Google può sfruttare questa posizione per imporre le sue regole nel nuovo panorama delle intelligenze artificiali?
Gli editori si trovano davanti a un vero e proprio dilemma: consentire lo scraping delle proprie pagine web senza ricevere alcun compenso o rischiare di perdere visibilità e, di conseguenza, profitti?
Secondo un’analisi di AdWeek, autorevole sito statunitense che si occupa di tecnologia e pubblicità, se le pagine non sono incluse nei snippet di Google e nei Discover della piattaforma si rischierebbe una riduzione del traffico organico fino al 60%!
Joe Ragazzo, sul sito Talking Points Memo, che si occupa di politica e media, ha descritto la situazione in termini piuttosto drastici: “Muori immediatamente oppure muori lentamente perché alla fine non avranno più bisogno di te”.
OK, un po’ drastico il ragazzo, ma la frustrazione di molti utenti è comprensibile.
Sì, perché questo non è solo un problema teorico: è una questione di sopravvivenza per molte testate giornalistiche e piccole-medie imprese che dipendono fortemente dal traffico generato da Google, come puoi ben capire.
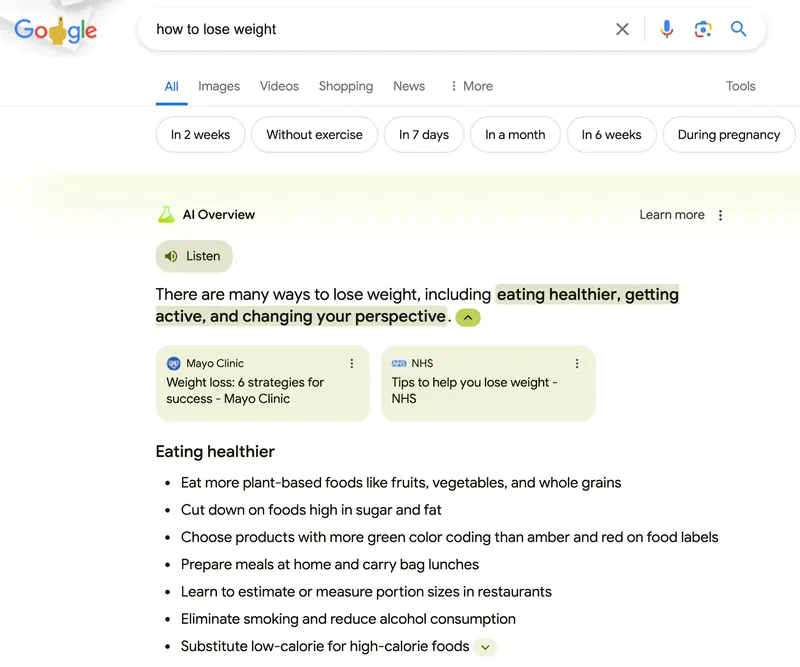
La questione web scraping: quando i dati sono la cosa più preziosa
Per comprendere pienamente la situazione, è utile fare un passo indietro e capire meglio cosa significa web scraping. Mi rendo conto che la questione è molto tecnica, ma ti chiedo la pazienza di seguirmi, perché si tratta di concetti fondamentali per il posizionamento dei siti web.
Bene, torniamo a noi, per web scraping si intende un processo attraverso il quale un programma o uno script estrae dati da un sito web, spesso senza il consenso esplicito del proprietario del sito.
Questo metodo è stato usato per anni da motori di ricerca come Google per creare indici del web, ma con l’avvento delle intelligenze artificiali, il valore di questi dati è salito alle stelle.
Devi sapere che per Google, il web scraping è parte integrante del suo modello di business: i suoi crawler, come Googlebot, scansionano il web per raccogliere informazioni che vengono poi utilizzate per alimentare sia i risultati di ricerca tradizionali che le nuove funzionalità di intelligenza artificiale.
Tuttavia, questo processo non è senza costi: per i proprietari dei siti web, essere scansionati significa utilizzare risorse di server, consumare banda e, talvolta, esporre i propri contenuti a utilizzi non autorizzati.
Un altro punto di tensione riguarda la gestione dei file robots.txt, che permettono ai proprietari dei siti web di stabilire regole su come i crawler possono interagire con le loro pagine.
Molti siti consentono a Google di scansionare liberamente i loro contenuti, ma bloccano altri crawler per evitare un eccessivo consumo di risorse o per proteggere i propri dati. Ma con l’integrazione sempre più stretta tra il motore di ricerca e l’intelligenza artificiale di Google (parlo di AI Overviews che davvero rivoluzionerà il web, non si scappa), questo sistema di regole sta diventando sempre più difficile da gestire.
Proprio a questo proposito, Richard Socher, fondatore di You.com, un piccolo (ma innovativo) motore di ricerca che utilizza le IA, ha commentato che i file robots.txt non sono legalmente vincolanti, ma che permettono comunque a Google di mantenere un monopolio de facto nel settore della ricerca, poiché la maggior parte dei siti web consente solo a Google (e non ad altri) di scansionare i propri contenuti.
Web scraping, privacy e diritto d’autore: una questione dirimente
A Mountain View non sono stati affatto sibillini (per una volta!) e hanno candidamente dichiarato a più riprese che tutto ciò che viene caricato pubblicamente online potrebbe essere utilizzato nei processi di training per gli attuali e futuri sistemi di intelligenza artificiale, rendendo ancora più difficile per i creatori di contenuti mantenere il controllo sui propri dati.
La recente causa contro OpenAI, sviluppatore di ChatGPT, per presunto scraping ha messo in luce i rischi associati a queste pratiche. Se da un lato i dati raccolti possono essere utilizzati per migliorare i servizi offerti, dall’altro, l’assenza di consenso esplicito solleva questioni etiche e legali non trascurabili.
Molti editori, che spesso dipendono dai motori di ricerca per almeno la metà del loro traffico, non sono disposti a correre il rischio di ridurre la propria visibilità.
Kyle Wiens, CEO di iFixit, un sito che offre guide di riparazione gratuite per elettronica, ha descritto il rapporto con Google come “molto più precario” rispetto ad altre aziende di intelligenza artificiale.
“Posso impedire a Claude di indicizzarci senza danneggiare il nostro business, ma se blocco Googlebot, perdiamo traffico e clienti!”
Ecco, mi sembra che questa frase non necessiti commenti ulteriori.
Ma allora mi chiedo (e ti chiedo): come possono piccole startup tentare di entrare nel mercato delle IA a queste condizioni?
Competere con Big G sul versante IA è (quasi) impossibile
L’ascesa dell’intelligenza artificiale generativa ha dato il via a una nuova ondata di startup che cercano di offrire prodotti di ricerca in cui i modelli di intelligenza artificiale forniscono risposte concise alle domande degli utenti.
Ma prima che queste startup possano davvero minacciare il business di un gigante della ricerca come Google, devono scansionare il web. E non è un’impresa facile.
Essere scansionati costa ai proprietari dei siti web in termini di denaro, potenza di calcolo e archiviazione, quindi molti editori includono un file che stabilisce le regole per i bot che visitano i loro siti.
Le aziende che godono della maggiore libertà in questo senso sono solitamente Google e Bing di Microsoft, che possono generare traffico verso i siti attraverso i loro motori di ricerca.
L’accordo di Google con Reddit ha offerto all’azienda un’ampia base di dati per i suoi modelli di intelligenza artificiale. Questa intesa ha coinciso con modifiche che hanno aumentato la visibilità dei risultati provenienti da forum come Reddit nelle ricerche, portando a un notevole incremento del traffico.
Comunque, come sai, Reddit ha siglato un accordo anche con OpenAI, confermando il fatto che ami giocare su più tavoli contemporaneamente…
Ma non solo, anche la startup di ricerca Perplexity (che prova a minacciare OpenAI e Google) è in trattative con Reddit per ottenere licenze sui contenuti, anche se l’accordo con Big G ha fissato un prezzo difficile da eguagliare!
Altre startup di ricerca invece hanno concluso che l’accesso ai dati è semplicemente fuori portata.
“Ci vorrebbero 20 anni del nostro attuale fatturato solo per pagare Reddit, non è nemmeno una possibilità che sto considerando!” ha dichiarato Vladimir Prelovac, fondatore di Kagi, un’altra piccola società che fa ricerca sulle IA.
Ma non solo piccole realtà vivono queste difficoltà, OpenAI che ha recentemente lanciato SearchGPT, ha registrato come Amazon, Goodreads e Uniqlo abbiano bloccato il crawler GPT, creando di fatto ostacoli difficili superare per competere ad armi pari con Big G.
Proprio per questo la proposta del Dipartimento di Giustizia USA di obbligare Big G a condividere i dati raccolti tramite Googlebot o a rendere accessibile il suo indice di ricerca ai rivali, potrebbe davvero aprire il mercato. (Il rischio di smembramento di Google, fidati, non è un’ipotesi così fantascientifica).
Ti ricordo poi che l’Unione Europea, attraverso il Digital Markets Act, richiede già a Google di condividere alcuni dati di ricerca (ma una cosa è “richiedere”, l’altra è “obbligare”…).
Comunque, indipendentemente dall’esito del caso Antitrust, tutto ciò evidenzia un sentire comune da parte di molti editori: quello di mantenere il controllo sul proprio destino e di non dipendere eccessivamente da una sola piattaforma tecnologica, anche se questa si chiama Google.
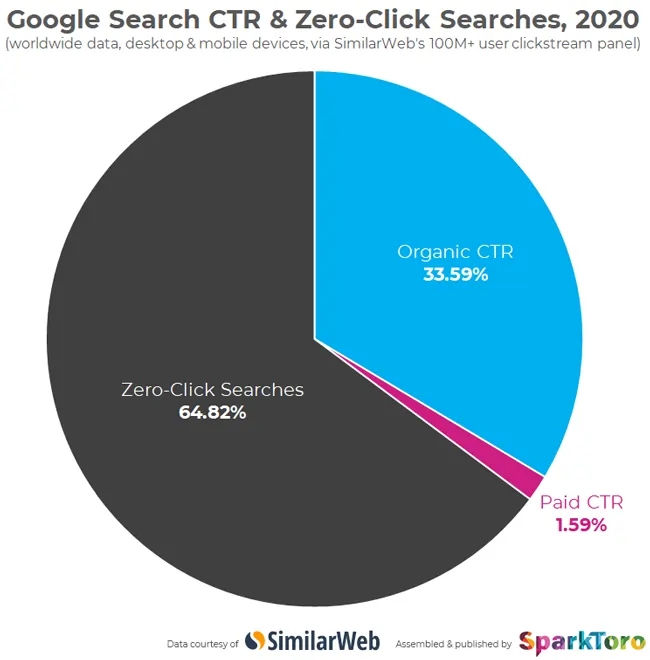
Il futuro a zero-click sta arrivando…
Abbiamo visto quanto la situazione sia complessa.
Ricapitolando: gli editori che decidono di impedire a Google di utilizzare i propri contenuti per l’IA rischiano di perdere visibilità e traffico, mettendo a repentaglio la loro sostenibilità economica.
Mentre, al contrario, coloro che acconsentono allo scraping potrebbero trovarsi in una posizione di dipendenza sempre maggiore da Google, con il rischio di vedere ridotta la propria autonomia editoriale, come rilevano ottimamente Julia Love e Davey Alba su Bloomberg.
Ecco, come vedi la questione è davvero ingarbugliata!
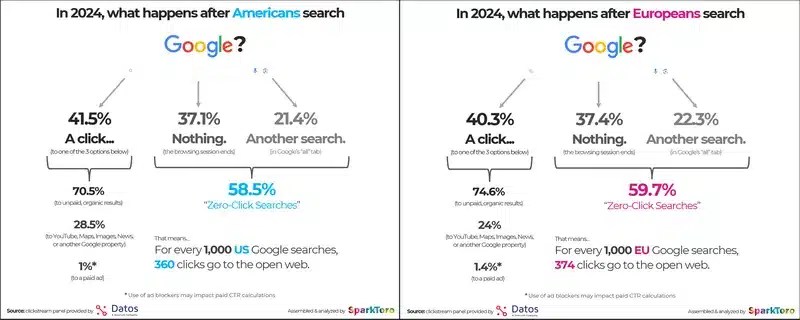
Non dimenticare poi un aspetto altrettanto importante: chi cerca un’informazione su AI Overviews la trova direttamente sul motore di ricerca (o sarebbe meglio dire “motore di risposta”), e non clicca sul sito web negandogli un riconoscimento economico, oltre che “autoriale!”
Insomma, oltre il danno la beffa: Google prende il tuo contenuto e ti nega perfino il click! Proprio per questo motivo, si parla di un futuro a zero-click con AI Overviews…
E tu, cosa faresti?
Permetteresti a Google di utilizzare i tuoi contenuti per generare risposte automatiche, rischiando di perdere parte del controllo su ciò che crei (e vedendo ridurre il tuo traffico), oppure ti opporresti, accettando il rischio di scomparire dai risultati di ricerca?
Non me ne vorrai se ti lascio con questo dilemma esistenziale, ma ti anticipo che questo sarà un tema al centro del dibattito nel mondo SEO ancora per molto tempo.
Takeaways
- Google potrebbe ridurre la visibilità dei siti che impediscono l’uso dei propri contenuti per le risposte automatiche dell’IA, penalizzando così il traffico organico. I proprietari di siti si trovano di fronte a un difficile dilemma: perdere visibilità o cedere i propri contenuti senza compenso.
- Il web scraping, utilizzato da Google per costruire il suo indice di ricerca, è fondamentale per l’IA generativa. Bloccare Googlebot può comportare una significativa perdita di traffico, mentre consentire lo scraping senza restrizioni potrebbe esporre i dati a utilizzi non autorizzati.
- Molti editori, che dipendono fortemente dal traffico di Google, devono scegliere tra mantenere la propria visibilità e rischiare di essere penalizzati, oppure proteggere i propri contenuti a costo di ridurre il proprio pubblico.
- Con AI Overviews, gli utenti trovano le risposte direttamente nella pagina dei risultati di Google, riducendo drasticamente il traffico verso i siti originali. Questo crea un futuro “zero-click”, in cui i contenuti vengono sfruttati senza generare ritorni per i creatori.
- Per garantire una maggiore equità nel mercato, il Dipartimento di Giustizia degli Stati Uniti sta considerando la possibilità di obbligare Google a condividere il proprio indice di ricerca con i concorrenti, una mossa che potrebbe ridurre il monopolio e aprire nuove opportunità per le startup.
FAQ
Google sta penalizzando i siti che non autorizzano l’uso dei loro contenuti per AI Overviews?
Secondo molti esperti SEO, sembra che Google stia penalizzando i siti che non permettono alle sue intelligenze artificiali di utilizzare i loro contenuti per generare risposte automatiche. Questo potrebbe portare a una drastica riduzione della visibilità nei risultati di ricerca.
Cedere i propri contenuti ad AI Overviews o no?
Gli editori si trovano davanti a un dilemma: consentire lo scraping delle proprie pagine web senza ricevere compenso o rischiare di perdere visibilità e profitti. La riduzione del traffico organico potrebbe arrivare fino al 60% se le pagine non sono incluse nei snippet di Google.
Quali sono le implicazioni del web scraping per i siti web?
Il web scraping è un processo utilizzato da Google per raccogliere informazioni dal web e alimentare sia i risultati di ricerca che le funzionalità di intelligenza artificiale. Tuttavia, questo può comportare costi per i proprietari dei siti in termini di risorse di server e può esporre i contenuti a utilizzi non autorizzati.
